Glossar: zentrale Begriffe
Folgende Hilfstexte stehen unter den jeweiligen Menüpunkten auch bei den blauen Fragezeichen-Buttons in Popup-Fenstern zur Verfügung.
1. Volltextsuche vs. Tokensuche
1. Volltextsuche vs. Tokensuche
Für die Volltextsuche werden Metadatendokumente und Transkripte als einfache Volltexte ohne Berücksichtigung zusätzlicher Dokumentstrukturen indiziert. Die
Volltextsuche eignet sich daher besonders für Suchanfragen, mit denen die Archivbestände nach inhaltlichen Stichworten (z.B. alle Transkripte, in denen über
Weihnachten gesprochen wird) durchsucht werden sollen. Die Volltextsuche liefert eine Liste von Dokumenten als erstes Suchergebnis.
Für die Tokensuche wird die
Strukturierung der Transkripte nach Sprecherbeiträgen, Wörtern etc. berücksichtig. Die Tokensuche eignet sich daher besser für Suchanfragen, mit denen Korpora
gezielt nach sprachlichen Formen als Grundlage einer (korpus)linguistischen Analyse durchsucht werden sollen (z.B. alle Vorkommen des Modalverbs "müssen". Die
Tokensuche liefert eine Liste von einzelnen Suchtreffern als erstes Suchergebnis.
Virtuelle Korpora können bei der strukturierten Tokensuche (Recherche > Tokens) verwendet werden. Anstatt der Korpusauswahl über die Kästchen in der Liste links wird die Option "Virtuelles Korpus laden" oben angeklickt und dann ein zuvor selbstzusammengestelltes und gespeichertes Teilkorpus für die folgende Suche ausgewählt (eine detaillierte Anleitung, auch zu Bestellungen virtueller Korpora über den Service des AGD, findet sich als Link zu einer PDF-Datei unter "Meine DGD" auf der Überblicksseite unter "Dateimanager").
▲ Seitenanfang
Kollektionen sind Sammlungen von Transkriptausschnitten.
Um neue Kollektionen zu erstellen oder vorhandene zu erweitern, rufen Sie in der Transkriptanzeige (Korpora >
Transkripte oder in der Anzeige von Ausschnitten in der KWIC-Ansicht unter Recherche > Tokens)
das Kontextmenü für einen Beitrag auf:
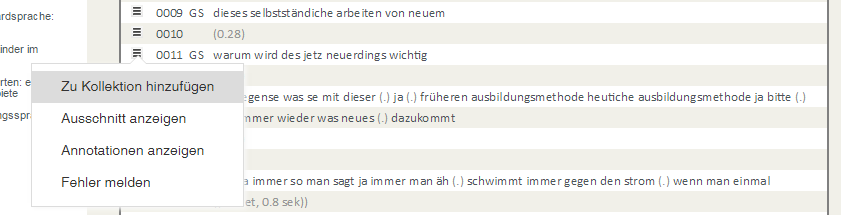
Für die gesamte Kollektion haben Sie folgende Möglichkeiten:
 öffnet eine geteilte Kollektion.
öffnet eine geteilte Kollektion.
 speichert die aktuelle Kollektion.
speichert die aktuelle Kollektion.
 invertiert die aktuelle Auswahl in der Kollektion.
invertiert die aktuelle Auswahl in der Kollektion.
 löscht abgewählte Einträge in der aktuellen Kollektion.
löscht abgewählte Einträge in der aktuellen Kollektion.
Für jeden Transkriptausschnitt haben Sie folgende Möglichkeiten:
 blendet den Transkriptausschnitt aus.
blendet den Transkriptausschnitt aus.
 vergrößert den Transkriptausschnitt.
vergrößert den Transkriptausschnitt.
 öffnet den momentan angezeigten Transkriptausschnitt in einem eigenen Browser-Tab und bietet Möglichkeiten zum Download des Ausschnitts an.
öffnet den momentan angezeigten Transkriptausschnitt in einem eigenen Browser-Tab und bietet Möglichkeiten zum Download des Ausschnitts an.
 wechselt zwischen Beitragsliste und Partituransicht (nur bei FOLK, GWSS und MEKI).
wechselt zwischen Beitragsliste und Partituransicht (nur bei FOLK, GWSS und MEKI).
Kollektionen werden seitenweise mit nicht mehr als 10 Einträgen pro Seite angezeigt.
Nutzen Sie die Drucken-Funktion Ihres Browsers, um eine solche Seite auszudrucken (Bedienungselemente der Bildschirm-Version werden
im Druck automatisch ausgeblendet).
Über den Dateimanager (Meine DGD > Dateimanager) haben Sie die Möglichkeit, alle gespeicherten Kollektionen anzusehen und zu verwalten.
Über den Menüpunkt Download können Sie ausgewählte Datensätze aus einzelnen Korpora komplett - d.h. mit Audio, Transkription und
Metadatendokumentation - herunterladen.
Klicken Sie auf die Kennung eines Datensatzes, um die zugehörige Ereignisdokumentation aufzurufen.
Klicken Sie auf das Download-Symbol, um den betreffenden Datensatz herunterzuladen.
Der Datensatz wird als ZIP-Datei bereitgestellt und enthält folgende Dateien:
- Eine Datei mit der Endung .fln. Dies ist das Transkript, das Sie mit den Tools OrthoNormal oder FOLKER (erhältlich über die Website des AGD) öffnen, bearbeiten oder in andere Formate konvertieren können.
- Eine Datei mit der Endung .html. Dies ist eine Visualisierung des Transkripts, die Sie mit einem beliebigen Webbrowser öffnen können.
- Eine Datei mit der Endung .WAV. Dies ist die Audiodatei.
- Eine oder mehrere Datei(en) mit der Endung .xml. Diese enthalten die vollständige Ereignisdokumentation (Datei *_E_*.xml) und die zugehörigen Sprecherdokumentationen (Dateien *_S_*.xml)
- Eine Datei mit der Endung _e_doc.html. Dies ist eine Kompaktansicht der Ereignisdokumentation, die Sie mit einem beliebigen Webbrowser öffnen können.
- Da die Datensätze unkomprimierte WAV-Dateien von einer Größe bis zu 700MB enthalten, können die Vorbereitung des Downloads und der Download bis zu einigen Minuten dauern.
- Für die heruntergeladenen Datensätze gelten die allgemeinen Nutzungsbedingungen der DGD.
- Um die Verknüpfungen zwischen Transkript- und Audiodatei nutzen zu können, müssen Sie die Dateien zunächst entpacken.
Die KWIC-Ansicht zeigt Suchergebnisse in Form einer Keyword-In-Context-Concordance (KWIC) an.
Das Suchergebnis selbst befindet sich rot und fett markiert in der Mitte, links und rechts davon werden bis zu 20 Wörter des umgebenden Kontexts angezeigt.
In zusätzlichen Spalten werden das zum Suchergebnis gehörende Ereignis sowie der zugehörige Sprecher angegeben.
In der KWIC-Ansicht...
Nutzen Sie die Checkbox, um ein einzelnes Suchergebnis an- oder abzuwählen.
Klicken Sie auf die Einträge in der Ereignis- oder Sprecherspalte, um die zugehörige Metadaten-Dokumentation anzuzeigen.
 spielt den Audioausschnitt für ein Suchergebnis ab.
spielt den Audioausschnitt für ein Suchergebnis ab.
![]() blendet den Transkriptausschnitt für ein Suchergebnis ein.
Darin kann wiederum durch einen Doppelklick auf einer beliebigen Stelle das zugehörige Audio abgespielt werden.
blendet den Transkriptausschnitt für ein Suchergebnis ein.
Darin kann wiederum durch einen Doppelklick auf einer beliebigen Stelle das zugehörige Audio abgespielt werden.
lädt Audio- und Transkriptausschnitt für ein Suchergebnis herunter.
Klicken Sie auf den Kopf einer Tabellenspalte, um das Suchergebnis nach dieser Spalte zu sortieren. Sprecher werden dabei nach ihrer DGD-Kennung,
nicht nach der Transkriptsigle sortiert.
Suchergebnisse können nur bis zu einer Maximalgröße von 1000 Treffern sortiert werden.
Reduzieren Sie die Größe des Suchergebnisses ggf. durch Entnahme einer Zufallsstichprobe.
Benutzen Sie die Buttons  und
und  , um zu folgenden
bzw. vorherigen Suchergebnissen in der Liste zu blättern.
, um zu folgenden
bzw. vorherigen Suchergebnissen in der Liste zu blättern.
Im Menü für die KWIC-Ansicht...
 stoppt das Abspielen des Audios.
stoppt das Abspielen des Audios.
 öffnet ein zuvor gespeichertes Suchergebnis.
öffnet ein zuvor gespeichertes Suchergebnis.
ermöglicht das Speichern des Suchergebnisses unter einem neuen oder vorhandenen Namen.
 öffnet eine Vollansicht der KWIC in einem neuen Browsertab.
Diese kann gedruckt oder für eine Weiterbearbeitung (z.B. in Excel) gespeichert werden (maximal 1000 Suchergebnisse).
öffnet eine Vollansicht der KWIC in einem neuen Browsertab.
Diese kann gedruckt oder für eine Weiterbearbeitung (z.B. in Excel) gespeichert werden (maximal 1000 Suchergebnisse).
 erstellt eine tabulator-separierte Textdatei der KWIC und stellt sie zum Download bereit (maximal 1000 Suchergebnisse).
erstellt eine tabulator-separierte Textdatei der KWIC und stellt sie zum Download bereit (maximal 1000 Suchergebnisse).
 entnimmt aus einem größeren Suchergebnis eine Zufallsstichprobe.
entnimmt aus einem größeren Suchergebnis eine Zufallsstichprobe.
 mischt das Suchergebnis zufällig durch.
mischt das Suchergebnis zufällig durch.
 entfernt alle derzeit angewendeten Filter aus der KWIC.
entfernt alle derzeit angewendeten Filter aus der KWIC.
invertiert die derzeit angewendeten Filter in der KWIC.
entfernt alle ausgefilterten Suchergebnisse aus der KWIC.
Bei eingeblendetem Transkriptausschnitt...
blendet den Transkriptausschnitt wieder aus.
vergrößert den Transkriptausschnitt (bis zu einer Maximalgröße von etwa einer Minute).
lädt den momentan angezeigten Transkriptausschnitt mit dem zugehörigen Audio herunter.
wechselt zwischen Beitragsliste und Partituransicht (nur bei FOLK).
Die Metadatenliste zeigt die Ereignisse und ggf. die zugehörigen Sprecher an, die zu den Suchkriterien passen.
In der Liste...
Nutzen Sie die Checkbox, um ein einzelnes Suchergebnis an- oder abzuwählen.
Klicken Sie auf die Einträge in der Ereignis- oder Sprecherspalte, um die zugehörige Metadaten-Dokumentation anzuzeigen.
![]() öffnet einen neuen Tab mit einem Player, um das Audio zum Suchergebnis abzuspielen.
öffnet einen neuen Tab mit einem Player, um das Audio zum Suchergebnis abzuspielen.
![]() öffnet das zugehörige Transkript (sofern vorhanden) in einem neuen Tab.
öffnet das zugehörige Transkript (sofern vorhanden) in einem neuen Tab.
spielt eine Hörprobe für ein Suchergebnis ab.
Im Menü für die Liste...
öffnet ein als virtuelles Korpus gespeichertes Suchergebnis.
ruft ein geteiltes virtuelles Korpus ab.
speichert das aktuelle Suchergebnis als virtuelles Korpus. Dieses kann dann auch bei der Token-Suche als virtuelles Korpus verwendet werden.
 berechnet eine Quantifizierung für das aktuell angezeigte Suchergebnis (öffnet sich in einem neuen Tab).
berechnet eine Quantifizierung für das aktuell angezeigte Suchergebnis (öffnet sich in einem neuen Tab).
entfernt alle derzeit angewendeten Filter aus der Liste.
invertiert die derzeit angewendeten Filter in der Liste.
entfernt alle ausgefilterten Suchergebnisse aus der Liste.
Nach dem Ausführen einer Tokensuche können Sie die Suchergebnisse nach Tokens in ihrem linken (vorhergehenden)
oder rechten (nachfolgenden) Kontext filtern.
Zum Beispiel können Sie nach einer Suche nach dem Token eigentlich den linken Kontext nach dem Token denn filtern und erhalten so
Fundstellen für die Tokenkombination denn (...) eigentlich.
Die Spezifikation des/der Kontext-Token(s) erfolgt dabei analog zur eigentlichen Tokensuche:
Sie können nach transkribierten, normalisierten und/oder lemmatisierten
Formen sowie POS-Tags mit Hilfe von einfachen Zeichenketten-Abgleichen oder mit regulären Ausdrücken suchen.
Zusätzlich können Sie folgende Parameter festlegen:
- Kontextmenge: Wählen Sie hier einen Zahlenwert aus, der festlegt, welche Menge an Kontext (z.B. 5 Tokens um die Fundstelle herum) beim Filtern einbezogen wird.
- Kontextrichtung Wählen Sie links, um nur den linken (vorhergehenden), rechts, um nur den rechten (nachfolgenden) und beidseitig, um linken und rechten Kontext der Fundstelle einzubeziehen.
- Skopus Wählen Sie Beitrag, um nur Kontext aus dem selben Beitrag wie die Fundstelle einzubeziehen. Wählen Sie Sprecher, um Kontext aus allen Beiträgen, die den selben Sprecher wie die Fundstelle haben, einzubeziehen. Wählen Sie Transkript, um beliebigen Kontext aus dem Transkript einzubeziehen.
Nach dem Anwenden eines Kontext-Filters werden alle Suchergebnisse, die den Filterbegriff nicht enthalten, als ausgefiltert markiert.
In den Suchergebnissen, die den Filterbegriff enthalten, wird dieser in den betreffenden Spalten der KWIC fett markiert.
- Die Verwendung regulärer Ausrücke verlangsamt die Suche. Aktivieren Sie diese Option nur, wenn Sie sie benötigen.
- Die Abstandsberechnung von Tokens erfolgt auf der Grundlage der jeweiligen Dokumentpositionen. Die Simultaneität von Äußerungen wird nicht in die Abstandsberechnung einbezogen.
Bevor sie eine Tokensuche ausführen, können Sie die Suche auf bestimmte Positionen in der Gesprächsstruktur beschränken.
Dazu gehören zum Beispiel Positionen in der Nähe von Sprecherwechseln, in der Umgebung von Pausen oder in Relation zu einer Sprecherüberlappung.
Zum Beispiel können Sie die Suche nach dem Token aber auf die Position (4) höchstens N Wörter nach einem Sprecherwechsel mit
dem Parameter-Wert N=1 beschränken und erhalten so Treffer, bei denen ein Sprecher einen neuen Turn mit dem Wort aber beginnt.
Um eine Position festzulegen, wählen Sie zunächst eine Vorlage aus der Liste aus. Die einzelnen Vorlagen sind in diesem
PDF-Dokument näher erläutert.
Manche Vorlagen erfordern zusätzlich die Wahl eines Parameters.
Numerische Parameter (z.B. 3, um bei der Vorlage
(2) höchstens N Wörter nach Beginn eines Beitrags die Suche auf die ersten drei Wörter eines Beitrags zu beschränken) geben
Sie im Feld N= ein.
Zeichenketten (z.B. Lachansatz für Vorlage (10) direkt vor einem non-verbalen Ereignis mit Beschreibung XXX)
geben Sie im Feld XXX= ein.
Nachdem Sie die Position spezifiziert haben, können Sie die Suche im Reiter Token weiter spezifizieren und ausführen.
- Die gesprächsstruktursensitive Suche kann nicht mit der Verwendung regulärer Ausdrücke kombiniert werden.
- Die gesprächsstruktursensitive Suche steht nur für das Korpus FOLK zur Verfügung.